Un aspetto molto importante di un interprete BASIC è la gestione delle stringhe. Può essere fatta in due modi: utilizzando stringhe statiche oppure stringhe dinamiche.
This is the Italian version of the already published article: “Garbage collection on the Commodore 64, how to handle it”.
Nel BASIC 2.0 del Commodore 64, le stringhe sono dinamiche: non hanno una lunghezza fissa. Ogni stringa può avere una lunghezza da 0 caratteri (stringa nulla) a 255 caratteri e può essere modificata in qualsiasi momento all’interno di un programma. Ciò permette di avere flessibilità ma a fronte di uno svantaggio abbastanza importante, come vedremo a breve.
Alcuni BASIC, come il BASIC Sinclair o il BASIC Atari, usano stringhe statiche. Ciò significa che le stringhe, una volta create, hanno una lunghezza fissa. Ad esempio, nel BASIC Sinclair, è possibile creare una variabile stringa avente lunghezza qualsiasi. Ma, una volta creata, questa dovrà avere sempre quella lunghezza. Lo stesso concetto vale per gli array stringa.
Nel BASIC del Commodore 64, anche se un array è stato già creato, è comunque possibile assegnare ad un qualsiasi suo elemento una nuova stringa più lunga di quella vecchia, senza che si verifichi alcun troncamento. Nelle stringhe statiche, invece, la lunghezza massima comune a tutti gli elementi deve essere scelta con molta attenzione, di modo che sia possibile collocare nell’array stringhe di differente lunghezza. Se una stringa dovesse essere più lunga di quel limite, questa sarà troncata.
Quindi, apparentemente, l’uso delle stringhe dinamiche può sembrare migliore dell’uso di quelle statiche, ma non è sempre vero. La gestione delle stringhe nel Commodore 64 ha un evidente limite progettuale. Questo problema viene chiamato “garbage collection lenta“. Non è un problema esclusivo del Commodore 64, ma è correlato a diversi modelli di computer ad 8 bit facenti uso del BASIC Microsoft. Ad un certo punto la Commodore risolse il problema, e le “nuove” versioni del CBM BASIC (BASIC 3.5, 4.0 e 7.0) non soffrono di questo inconveniente.
Garbage collection
Utilizzando stringhe dinamiche, lo spazio di cui queste hanno bisogno deve essere opportunamente allocato. Siccome la loro lunghezza è variabile, il procedimento non è molto diretto. Quando si crea una variabile stringa, il suo nome, la sua lunghezza ed un puntatore vengono memorizzati nell’area delle variabili. Nome, lunghezza e puntatore costituiscono un descrittore. Il puntatore indica all’interprete BASIC dove si trova in memoria il contenuto della stringa. Se all’interno di un programma si ha un’istruzione quale B$ = “HOME”, il puntatore farà riferimento soltanto a quella parte del programma contenente la parola HOME. Invece, se un programma ha un’istruzione del tipo B$ = CHR$(65), verrà creata in memoria una stringa contenente il carattere “A”. Il puntatore di B$ punterà ad una locazione di una specifica area di memorizzazione destinata all’immagazzinamento delle stringhe. Ecco dove il contenuto di B$, il carattere “A”, verrà memorizzato.
Operatori stringa quali CHR$ e STR$ possono produrre dei rifiuti (garbage), cioè delle stringhe che vengono create al momento, memorizzate nell’area delle stringhe ma non più usate. D’altro canto, se una variabile viene riassegnata, verrà creata una nuova stringa (più lunga o più corta della vecchia), e il puntatore di quella variabile farà riferimento proprio alla nuova stringa creata. La vecchia stringa diventerà inutilizzata, ma rimarrà ancora in memoria. In questo momento, lo spazio occupato da essa non sarà recuperato. Questa stringa è stata dunque sostituita ed è diventata un rifiuto.
L’area di immagazzinamento delle stringhe viene creata dal Top of BASIC (TOB). Nel Commodore 64, il byte basso e il byte alto dell’indirizzo del Top of BASIC vengono memorizzati nelle locazioni 55 e 56 decimali. L’area di immagazzinamento delle stringhe “cresce all’indietro” a partire da quella locazione. Quest’area è fra il TOB e l’indirizzo di Fine delle Variabili (in realtà, questo indirizzo è chiamato Fine degli Array).
La “Fine degli Array” è l’indirizzo finale dell’intera area di immagazzinamento delle variabili (cioè l’area dove vengono memorizzate le variabili numeriche e gli array numerici, nonché le variabili stringa e i descrittori delle stringhe degli arrray).
Si osservi che creando un array stringa avvengono due cose. Quando l’array viene dimensionato, vengono subito creati nell’area delle variabili (nella porzione riservata agli array) i descrittori per tutti gli elementi dell’array. Quando poi gli elementi dell’array vengono assegnati, vengono create delle stringhe nell’area di immagazzinamento delle stringhe. Ciascun puntatore contenuto nei descrittori dell’array farà riferimento ad una di esse.
Pertanto, quando viene creato un array e i suoi elementi vengono via via assegnati, l’area di immagazzinamento delle stringhe si muove verso il basso, andando incontro alla Fine degli Array.
Quando vengono create molte stringhe, sia come conseguenza dell’assegnazione di variabili o array stringa, sia come risultato della manipolazione di stringhe che produce rifiuti, l’area di immagazzinamento delle stringhe diviene sempre più grande, andando verso la Fine degli Array.
Ad un certo punto, la memoria comincia a diventare piena, e deve essere attuata una qualche azione volta a recuperare lo spazio utilizzato dai rifiuti. Il BASIC 2.0 contiene una routine progettata per questo, chiamata “Garbage collector”. Essa effettua l’operazione definita come “Garbage collection”. In poche parole, effettuando una scansione dei puntatori delle variabili stringa esistenti e degli array, essa realizza una “deframmentazione” dell’area di immagazzinamento delle stringhe, di modo che le stringhe utili sono tutte adiacenti tra di loro, “rimuovendo” i rifiuti. Il processo deve essere realizzato con molta attenzione, di modo che le stringhe utili non vengano danneggiate.
Purtroppo, questa routine può essere molto lenta. Siccome deve scansionare ciascuna variabile stringa e ciascun elemento degli array stringa, se ci sono molte variabili e array stringa in memoria il processo sarà molto lento. In alcuni casi, possono essere necessari alcuni minuti o addirittura ore per il completamento del processo. Quindi, nel caso in cui si utilizzino delle stringhe, è necessaria una programmazione molto attenta.
Valutare la velocità della garbage collection
Si consideri il seguente programma:
5 dim a$(800) 10 for t = 1 to 800 20 a$(t) = "a" 30 next t 40 print "garbage collection..." 50 print fre(0) 60 print "done."
L’istruzione PRINT FRE(0) viene usata per visualizzare la quantità di memoria libera per il BASIC, ma in realtà richiama anche la routine di garbage collection. Equivalentemente, un’istruzione del tipo X = FRE(0) farà comunque avviare tale routine.
Se si esegue il precedente programma, si vedrà che il processo di garbage collection sarà istantaneo, poiché il programma non ha prodotto alcun rifiuto. Nella linea 20, l’assegnazione A$ = “A” non produce alcun rifiuto perché il contenuto di A$ viene preso direttamente dal testo del programma e di conseguenza non è stata creata alcuna stringa rifiuto.
Tuttavia, se si modifica la linea 20 in:
20 a$(t) = chr$(65)
si noterà che, questa volta, la routine di garbage collection richiederà un po’ di tempo. Ciò è dovuto al fatto che l’operatore stringa CHR$ crea una stringa che viene memorizzata nell’Area di Immagazzinamento delle stringhe e diventa un rifiuto. Questo avviene in ogni iterazione, quindi il ciclo FOR… NEXT del precedente programma produce molte stringhe rifiuto.
Se si riduce la dimensione dell’array, ad esempio a 400 elementi, si vedrà che la garbage collection sarà molto più veloce. Nonostante la dimensione dell’array sia stata dimezzata, il processo richiede ora in realtà soltanto un quarto del tempo richiesto in precedenza. Ciò significa che, col crescere del numero delle variabili stringa in memoria, il garbage collector diviene più lento in ragione del quadrato del numero delle variabili stringa presenti in memoria. Quindi, nel manipolare grandi array stringa, il tempo richiesto per la garbage collection diventerà con ogni probabilità molto grande.
Come risolvere il problema
Il seguente programma mostra chiaramente i problemi che possono verificarsi a causa di una lenta routine di garbage collection.
5 rem not working program 10 dim a$(4600) 20 for t = 1 to 4600 30 a$(t) = "#" + str$(t) 40 print t : next
Questo programma è una tipica “routine assassina”. Una manipolazione di stringhe all’interno di un loop crea con molta probabilità tantissimi rifiuti. In questo caso, i rifiuti vengono prodotti dalla linea 30. I rifiuti vengono creati dall’operatore STR$, che converte in stringa il numero contenuto dalla variabile T. Viene poi creata una stringa con il risultato della concatenazione e questa viene assegnata all’elemento A$(T). Queste stringhe vengono collocate nell’Area di Immagazzinamento delle Stringhe, in quell’ordine. Quindi, durante ogni loop, la routine crea una stringa buona ed una rifiuto. Via via che il programma viene eseguito, l’area di immagazzinamento delle stringhe viene popolata da stringhe buone e da stringhe rifiuto, mescolate tra di loro. Ciò comporta un alto livello di deframmentazione.
Ad un certo punto, l’area di immagazzinamento delle stringhe diviene molto grande, e la sua base si avvicina sempre più all’indirizzo di Fine degli Array. A questo punto, viene attivata la routine di garbage collection, ma il computer sembra “morto”. Ci sono migliaia di elementi array da scansionare. Il programma impiegherà ore per cercare di terminare, e nemmeno riuscirà a terminare producendo l’errore “?OUT OF MEMORY ERROR”, a causa del fatto che l’array è troppo grande per poter essere contenuto nella memoria disponibile per il BASIC.
L’operatore STR$ aggiunge uno spazio davanti al numero convertito in stringa. Questo spazio aggiunge un byte inutile a ciascun elemento dell’array. Troncare questo spazio in modo da ridurre la memoria occupata dall’array è possibile, ma questo richiede un’operazione stringa aggiuntiva all’interno del loop. Ciò non farebbe altro che creare ancora più rifiuti.
Provare a ripetere l’operazione di garbage collection all’interno del programma non è a sua volta di nessun aiuto. Anzi, non fa altro che rallentare ulteriormente il tutto! Infatti, durante l’esecuzione del programma le stringhe continuano ad aumentare, quindi ogni chiamata della routine di garbage collection sarà sempre più lenta, secondo la regola del quadrato del numero degli elementi!
Può a questo punto sembrare che non sia possibile creare un tale array con il BASIC del Commodore 64. Gli array stringa e i relativi descrittori sembrano occupare troppa memoria, i rifiuti prodotti dalla manipolazione delle stringhe alla fine riempiono la memoria e la routine di garbage collection fa semplicemente un disastro. Durante il processo di garbage collection, il tasto RUN/STOP non è attivo. Per uscire dal programma, si può almeno premere RUN/STOP e RESTORE.
Esiste tuttavia un rimedio e sono infatti riuscito a creare l’array con un piccolo e veloce programma BASIC. Il codice sarà mostrato alla fine di questo articolo.
Tuttavia, le prestazioni del programma possono essere migliorate molto effettuando più e più garbage collection locali.
Garbage collection locale
La routine di garbage collection effettuerà la scansione delle variabili stringa e degli array stringa soltanto a patto che ci siano delle stringhe nell’Area di Immagazzinamento delle Stringhe. Se facciamo in modo che prima di chiamare la routine risulti unicamente la presenza di pochi rifiuti e variabili, la routine stessa verrà eseguita in un tempo molto breve.
Diamo un ulteriore sguardo all’esempio che segue:
5 dim a$(800) 10 for t = 1 to 800 20 a$(t) = chr$(65) 30 next t 40 print "garbage collection..." 50 print fre(0) 60 print "done."
Dobbiamo ora conoscere un vettore molto importante: il puntatore all’Area di Immagazzinamento delle Stringhe. Esso tiene traccia dell’indirizzo attuale a partire dal quale deve essere immagazzinata una stringa. Il byte basso è nella locazione 51 decimale, il byte alto è nella locazione 52 decimale.
Ora, l’Area di Immagazzinamento delle Stringhe utilizzata è compresa dal Top of BASIC fino all’indirizzo al quale il puntatore delle stringhe fa riferimento. Quindi, se sostituiamo temporaneamente il Top of BASIC con l’indirizzo contenuto nel puntatore delle stringhe, la routine di garbage collection, se chiamata, penserà che non sono presenti rifiuti in memoria, e verrà eseguita istantaneamente. Se successivamente creiamo un po’ di stringhe e rifiuti e chiamiamo la routine di garbage collection, questa penserà che solo queste stringhe e questi rifiuti sono presenti in memoria, ed effettuerà il proprio lavoro molto rapidamente. E questo avverrà a prescindere dal numero di stringhe che erano presenti in memoria prima di modificare il puntatore TOB. Una volta che il processo è terminato, il TOB deve essere ripristinato al suo valore precedente, di modo che è possibile utilizzare tutte le variabili presenti in memoria.
L’esempio fornito in precedenza può essere modificato in modo da effettuare due garbage collection più veloci:
100 dim a$(800) 110 for j=1 to 400 120 a$(j)=chr$(65) 130 next j 140 print "garbage collection..." 150 print fre(0) 160 print "done" 210 a1=peek(55):a2=peek(56) 220 poke55,peek(51):poke56,peek(52) 240 forj=401to800:a$(j)=chr$(65):next 250 print"garbage collection...":print fre(0):print"done." 260 poke 55,a1:poke56,a2
Come si può vedere, gli elementi array vengono creati con due loop iterativi, ciascuno relativo a 400 elementi.
La prima volta, il garbage collector viene chiamato quando sono presenti in memoria soltanto 400 elementi. Quindi, la “raccolta” è più veloce che per 800 elementi. Questo si verifica anche nella seconda chiamata, ma prima di chiamare il collector, il puntatore TOB viene modificato. In questo modo, la seconda “raccolta” impiegherà lo stesso medesimo tempo della prima, nonostante erano già stati creati in precedenza 400 elementi array. Modificando il puntatore TOB, assegnandolo al Puntatore delle Stringhe, i 400 elementi array creati in precedenza e i rifiuti prodotti dalle precedenti iterazioni vengono semplicemente nascosti al collector.
Alla fine del programma, il TOB viene ripristinato cosicché tutte le variabili sono di nuovo accessibili.
Se si misura il tempo richiesto dal programma per la sua esecuzione, si noterà che rispetto alla precedente versione del programma, che esegue invece una garbage collection globale, vengono guadagnati alcuni secondi.
Se spezzettiamo ancora di più la garbage collection, avremo diverse garbage collection veloci, con il risultato di ottenere un tempo di esecuzione complessivo del programma ancora più breve.
Proviamo ad applicare questo principio alla precedente “routine assassina” che crea 4600 elementi e vediamo cosa succede. Per ora, riduciamo il numero di elementi a 4000, in modo da essere sicuri che l’array potrà essere contenuto nella memoria BASIC disponibile. E’ comunque possibile avere più elementi.
50 ti$="000000" 100 rem multi garbage split 110 dim a$(4000) 120 a1=0:a2=0:k1=1 125 a1=peek(55):a2=peek(56) 130 for si=1to40 135 poke 55,peek(51):poke56,peek(52) 140 for t=k1tok1+99:a$(t)="#"+str$(t):next 150 print fre(0):k1=k1+100:next 160 poke 55,a1:poke56,a2 170 print ti$
Come è possibile notare, il programma è ancora lento ma molto, molto più veloce ed efficace della precedente “routine assassina”. Vengono infatti creati 4000 elementi in “soli” 19 minuti. Per comodità, è ovviamente possibile eseguire il programma con l’emulatore VICE impostando la modalità “warp”.
Tutte le garbage collection richiedono lo stesso tempo per essere eseguite in quanto nel momento in cui viene fatta ciascuna chiamata, il garbage collector pensa che sono presenti solo 100 elementi dell’array e soltanto una frazione dei rifiuti.
Una volta eseguito il programma, è possibile visualizzare il contenuto dell’array immettendo la seguente linea di comando in modo diretto:
for t = 1 to 4000:print a$(t),:next
Come si può vedere, tutti gli elementi sono al loro posto.
Ora, per poter creare un aray da 4600 elementi come nella routine assassina originale, bisogna provare a troncare lo spazio aggiuntivo creato dall’operatore STR$. In questo modo, possiamo risparmiare un byte per ogni elemento dell’array.
50 ti$="000000" 100 rem multi garbage split 110 dim a$(4600) 120 a1=0:a2=0:k1=1 125 a1=peek(55):a2=peek(56) 130 for si=1to46 135 poke 55,peek(51):poke56,peek(52) 140 for t=k1tok1+99:a$(t)="#"+right$(str$(t),len(str$(t))-1):next 150 print fre(0):k1=k1+100:next 160 poke 55,a1:poke56,a2 170 print ti$
All’interno del loop è stata introdotta una manipolazione delle stringhe aggiuntiva, ma la tecnica delle numerose garbage collection locali funziona comunque. La routine richiede 25 minuti per poter essere eseguita… è sicuramente lenta, ma non sono più necessarie ore.
Il problema è che abbiamo comunque continuato ad usare la lenta routine di garbage collection. Per poter ottenere una esecuzione più rapida del programma, dobbiamo trovare un modo che ci permetta di creare l’array desiderato senza alcuna garbage collection.
Area statica di memorizzazione dei rifiuti
Nonostante il problema della garbage collection lenta, il seguente programma è in grado di creare il famoso array di 4600 elementi in soli 4 minuti e 29 secondi.

Il programma può essere scaricato qui: STATIC GARBAGE ROUTINE
Come si può vedere, il programma non chiama la routine di garbage collection. E non fa questo nemmeno l’interprete BASIC.
Il principio è il seguente: siccome le stringhe “rifiuto” sono usate soltanto una volta all’interno di ciascuna iterazione, perché lasciarle vivere in memoria inutilizzate per tutto il tempo? Se non abbiamo stringhe rifiuto, non c’è bisogno nemmeno di “ripulirle”.
Il programma crea un'”area statica dei rifiuti” che viene utilizzata indipendentemente dall’Area di Immagazzinamento delle Stringhe. Questo viene fatto in BASIC senza l’uso di routine aggiuntive. In questo modo, le stringhe rifiuto non sprecano più memoria. Queste vengono semplicemente create in continuazione in questa piccola area di memoria. La creazione di un’area statica per i rifiuti di 20 caratteri è sufficiente per questo programma.
Il programma funziona in questo modo. All’inizio del programma, viene memorizzato il valore corrente del puntatore alle stringhe (nelle variabili G1 e G2). Poi, viene eseguita un’istruzione di manipolazione delle stringhe “finta” (linea 10 del programma). Questa istruzione non fa niente di utile in apparenza, ma in realtà effettua un’operazione importante: essa definisce in memoria l’area di memorizzazione statica per i rifiuti mediante la creazione di una stringa rifiuto di 20 caratteri (i 20 spazi). Ora, il puntatore delle stringhe è appena al di sotto dell’area statica di memorizzazione, ed è pronto per scrivere in memoria altre stringhe. A partire da questa posizione verrano scritte delle stringhe UTILI (quelle alle quali farà riferimento l’array), quindi dobbiamo salvare il valore corrente del puntatore alle stringhe. Ciò viene fatto nella linea 15, prima del ciclo FOR… NEXT. S1 e S2 contengono il valore corrente del puntatore alle stringhe, che serve per la memorizzazione delle variabili stringa utili.
All’interno dell’iterazione, viene anzitutto recuperato il valore iniziale del puntatore alle stringhe. In questo modo, le stringhe rifiuto che verranno create d’ora in poi saranno collocate nell’area statica di memorizzazione delle stringhe rifiuto. Esattamente come volevamo.
Dopo che vengono eseguite le seguenti istruzioni (producendo rifiuti):
B$ = STR$(T) B$ = RIGHT$(B$, LEN(B$)-1)
al puntatore alle stringhe viene assegnato il valore contenuto nelle variabili S1 e S2. In questo modo, il puntatore alle stringhe ora punta all’area al di sotto dell’area statica di memorizzazione delle stringhe rifiuto, e sarà usata per la memorizzazione delle stringhe utili.
L’istruzione A$(T) = “#” + B$ crea a questo punto una stringa utile.
Ora, bisogna di nuovo salvare il valore corrente del puntatore alle stringhe. Quindi, le variabili S1 e S2 vengono aggiornate con quel valore, di modo che quando le stringhe utili saranno di nuovo create nella successiva iterazione, il puntatore alle stringhe potrà essere impostato in maniera tale che queste vengano scritte appena al di sotto delle precedenti stringhe utili.
Nella successiva iterazione, le istruzioni:
POKE 51,G1: POKE 52,G2
cambiano il puntatore alle stringhe di modo che esso punta di nuovo all’area statica di memorizzazione delle stringhe rifiuto. D’ora in poi, il ciclo continua come precedentemente descritto, fino a che vengono eseguite tutte le iterazioni.
E’ utile osservare che G1 e G2 rimangono inalterate durante tutte le iterazioni: le stringhe rifiuto vengono scritte in continuazione nella stessa area statica dei rifiuti di 20 caratteri. S1 e S2 vengono invece aggiornate, di modo che le stringhe dell’array possono essere via via memorizzate, una dopo l’altra.
Alla fine del programma è presente in memoria l’array desiderato e non è presente alcun rifiuto.
Un tale metodo di programmazione deve sicuramente essere usato con molta attenzione. I puntatori devono essere impostati correttamente. Ma, nonostante ciò, il codice è molto efficiente. Il principio può essere usato in qualunque programma, ad esempio modificando il puntatore alle stringhe quando necessario mediante l’utilizzo di semplici subroutine, riducendo così il rischio di incorrere in errori di programmazione.
Abbiamo ora un vantaggio rispetto agli interpreti basati sulle stringhe statiche. Possiamo aggiungere ad alcuni elementi dell’array anche stringhe lunghe, senza alcun problema. Ora che abbiamo creato un siffatto array con tutti questi numeri convertiti in stringa, ha sicuramente senso aggiungere ad esempio alcune note vicino ad alcuni numeri.
Se scriviamo l’istruzione A$(2600) = A$(2600) + “I LIKE MY ATARI 2600”, la stringa verrà assegnata correttamente, senza alcun troncamento.

Finché c’è memoria libera, possiamo ovviamente aggiungere delle note anche ad altri numeri.
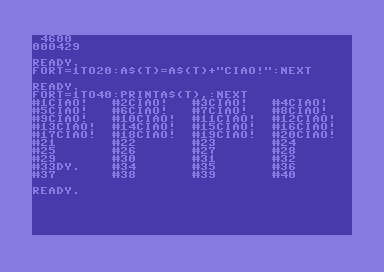
In una macchina con stringhe statiche, quella stringa lunga sarebbe stata semplicemente troncata. Per poter scrivere una tale nota, avremmo dovuto creare un array avente TUTTI gli elementi di quella lunghezza. Come è facile notare, ciò costituisce un grosso spreco di memoria, ed inoltre quello spazio sarebbe semplicemente impossibile da avere in alcuni se non nella maggior parte dei computer ad 8 bit.
Nei computer vintage, l’uso delle stringhe statiche sembra essere migliore per la gestione di grandi array contenenti stringhe molto corte aventi una comune lunghezza fissa. Per array di medie dimensioni contenenti stringhe di differente lunghezza, utilizzare delle stringhe dinamiche fornisce invece la flessibilità necessaria. Ad esempio, un compito quale la memorizzazione di un piccolo vocabolario può essere eseguito in modo migliore utilizzando le stringhe dinamiche, in quanto le varie parole possono avere lunghezze molto differenti.
Per ulteriori informazioni sull’argomento, potete consultare i seguenti documenti:
- https://www.c64-wiki.com/wiki/Garbage_Collection
- https://archive.org/details/1984-06-compute-magazine
- https://archive.org/details/1984-07-compute-magazine
Nella rivista Compute! potrete trovare degli eccellenti articoli sull’argomento scritti da Jim Butterfield.