Creating user defined characters on the Commodore 64 is not that easy from BASIC V2. Binary numbers – which can be useful for entering characters shapes – are not accepted. Furthermore, even changing a couple of characters actually requires that the whole ROM characters set is copied in RAM. That means, we have to copy 4K bytes from ROM to RAM – something quite slow in BASIC (but I am trying to figure out some tricks to speed things up). Still, if using standard programming techniques, a machine language routine is required for that. BASIC would need several seconds for the whole copying (using a FOR… NEXT cycle).
On the Sinclair Spectrum, changing a few characters is quite easy instead. And there’s no need to make reference to any memory address. For instance, the function USR “A” will return the address of the first byte of the user programmable character A. So, USR “A”+1 will return the address of the second byte and so on.
Binary numbers are supported by Sinclair BASIC. Just put a “BIN” statement before a binary number. For instance, BIN 01110011 will do.
The following simple code will create an “alpha” on the Sinclair Spectrum, replacing the user defined character “A”. The new character can be typed by entering in the graphics mode then typing “A”, or by using the ASCII code 144.
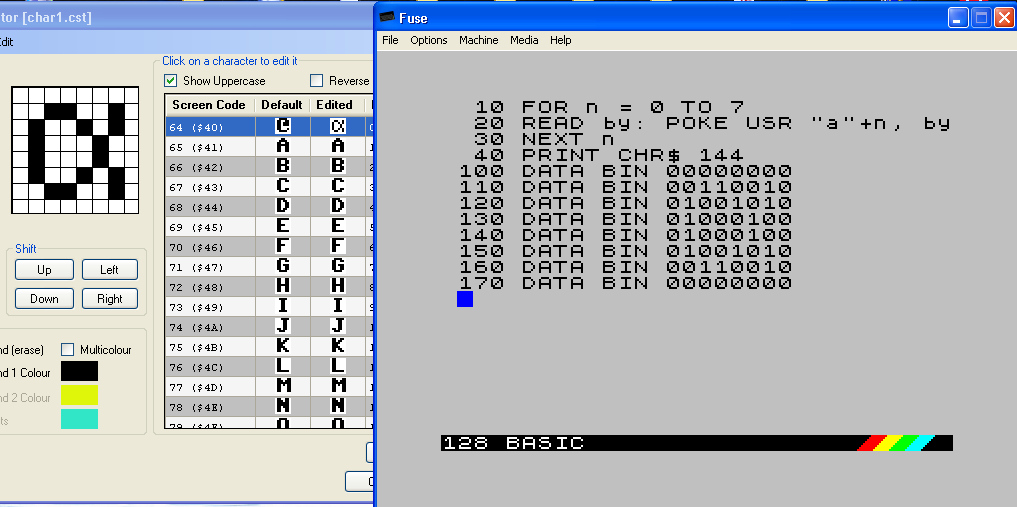
As you can see, each character row is entered via DATA statements using an 8 bit binary number. Naturally, 1 digits are associated to ON pixels, while 0 digits are associated to OFF pixels.
On the Commodore 64, we indeed have the advantage of having a hardware text mode, but doing the same thing as above is more complicated. Still, I have tried to code a very minimal yet effective font editing support program, mostly in BASIC V2. We have many tools today for creating characters on the Commodore 64, but still, I wanted to come up with an old-fashioned, simple poor man’s solution.
The program is quite minimal and offers features quite similar to what Sinclair BASIC offers.


Like on the Spectrum, now characters data can be entered via DATA statements, using binary numbers. Actually, those numbers are decimal, but it simply doesn’t matter for the code.
On line 1490, two important data are present:
- character screen code: it tells the program what character to modify;
- characters set to modify: since the standard Commodore font has two distinct characters set (upper case/graphics and upper/lower case), we must tell the program in which set the character to modify can be found. 0 is for upper case/graphics set, 1 is for the upper case/lower case one.
By poking location 1024 with 65 from direct mode (you may also need a POKE 55296, 14 on some older machines), you will soon realize that this screen code refers to a SHIFT+A character.
So, after you run the program, you will obtain an “alpha” with SHIFT+A (when using the upper case/graphics charset).
I have also added other characters, as you can see from the program listing. For instance, we now have a PI sign even in the upper case / lower case character set (something oddly missing on default). I have also slightly changed the “A” letter in the upper case/graphics charset.
You can easily define other characters. For each character, you just need a DATA line with the screen code and the charset of the character to be programmed. Then, you need eight DATA lines for the actual character shape.
Line 60000 signals that there are no more character shapes. Don’t remove it, otherwise you’ll get an OUT OF DATA error.
As usual, let’s have a look at the code.
Binary to decimal conversion
This is done in BASIC and the code is as follows:
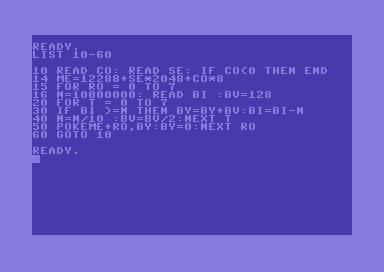
As you can see, each binary number BI is actually a decimal number, ranging from 0 to 11,111,111. Each binary number is compared with the number N. It starts from 10,000,000.
If a binary number is greater than or equal to N, then the current binary digit is a 1. If it is a 1, we need to add the matching bit value to the variable BY (the byte of a given character row), then we need to subtract N to BI.
If the current binary digit is 0 instead, we don’t update BY and we don’t subtract N to BI either. If we did it for mistake, we would clearly realize as we would have a negative BI.
After the first binary digit (bit 7, the highest one) has been checked, N is divided by 10, so that bit 6 can be checked on the next loop.
Bit values are updated by dividing BV by two on each loop. This is faster than using powers.
We have two nested loops. The inner loop performs the binary to decimal conversion for each character row, the outer loop reads the next character row. After each conversion is performed, the resulting decimal value BY is stored on the characters RAM memory.
As a BASIC routine, it cannot be fast. However, by only using numbers, it doesn’t create any memory wasting strings. The Commodore 64 User’s guide has a binary to decimal conversion program, but it makes use of strings. A binary number is actually seen as a string. Each binary digit is obtained by using the function MID$, then it is converted to either a 0 or a 1 number by using the function VAL. It does work, but MID$ will create temporary strings in memory.

Using numbers instead of strings also offers another advantage: we don’t have to deal with the quote mode while editing binary numbers in the listing.
Copying the Commodore ROM font from ROM to RAM
This task is accomplished by the subroutine starting from line 100. The character generator ROM lies under the I/O area. Normally, the I/O area can be used by the CPU for handling interface adapters (like the VIC-II and the SID for instance). The characters ROM cannot normally be read instead. To read it, we need to use the I/O port of the 6510 CPU (it can be found at location 1). We must make the characters ROM viewable by the CPU, so that it will be able to read it. As you can see from the code, interrupts are disabled during the copying process. This is because the 4K I/O area has been disabled to gain access to the 4K characters ROM. Any interrupt request would cause the system to crash. After characters have been copied in RAM, interrupts are turned back on.
The actual copying process is performed by a small, relocatable machine language subroutine. To make the program simple and old-stilish, this routine has been merged to the BASIC program by using DATA statements (this is acceptable for small routines – there’s a little memory waste and they are loaded in memory fast).
Source code: assembly copy routine
Indirect, indexed addressing mode has been used to move the bytes.
An instruction such as:
(*) lda ($fc),y
will load on the accumulator the content of the address obtained by the sum of the indirect address contained in locations $fc and $fd and the content of the Y index register.
ADDRESS = indirect address + Y register
So, if $fc contains the low byte of ROM charset starting address, $fd contains the high byte of that address, and the Y register contains 0, then the instruction (*) will load the accumulator with the content of the resulting address 53248 + Y = 53248 decimal.
If we then increment the Y register, we can gain access to locations 53248+1, 53248+2 and so on.
When we have reached the limit of 255 for Y, we have to increment $fd by one. Since $fd holds the high byte of the indirect address, that just means stepping one memory page further (that is, adding 256 decimal to the indirect address). Thus, by incrementing Y from 0 to 255 we will now reach the next 256 ROM locations.
The code for storing the ROM content in RAM is quite similar. The STA instruction is just used with that very same address mode. Locations $fe and $ff are used along with STA to hold the indirect address (which is starting from 12288 decimal, the base address for the RAM character set).
As you will have noticed, no self-modifying code has been used this time. Furthermore, there are no JMP/JSR instructions – only relative jumps are performed (using BNE instructions). So, the code can be relocated. That is quite useful, as you can put this routine anywhere in RAM and use it in your own programs.
Also, if you want to expand the program, you can put RAM characters on a different bank (on this code bank 0 has been used to keep things simple). And you’ll be free to move the machine language routine accordingly (you will only need to change the destination address of the copy in the routine).
Some tips for using Tiny Font Editor
As the binary to decimal conversion is coded in BASIC – and thus slow – this program is not suitable for defining many characters. It is just a minimal program to change some characters shapes. It may be seen as a cheap and simple solution that could have been used at the times to overcome the lack of a built-in character editor and binary numbers support on the C64 standard BASIC V2 environment.
When you have to run the program to update characters shapes, don’t use RUN. Issue RUN 5 instead. This way, you will skip the BASIC subroutine that draws the whole charset, making things faster.
While editing characters, pay attention to typos: only numbers 1 and 0 are accepted. Otherwise, an error will occur.
Once you are happy with your shapes, you can just save the whole program, maybe renaming it after the shapes you modified.
Of course, such simple programs are quite useless today, but I do believe that even minimal programs may be interesting, at least to review some topics.
Not specifically for this article, but I would like to express my appreciation for your interesting site.
And for your English proficiency, something we Italians are normally not particularly good at!
Keep up the good work!
Edoardo
Hello Edoardo! Many thanks for your kind words. My English is a bit rusted, but I am glad you appreciate it 🙂 Greetings!
Same comment as above. Your pages dedicated to C64’s programming are well written and very clear. It helped me a lot in improving my understanding of C64’s programming and learning machine language. I really enjoy reading them. Great job. Thank you!!!
In your assembly code for the copy routine, I would have rather used zero page addresses $fb/$fc and §$fd/$fe instead of $fc/$fd and $fe/$ff. The zero page address $ff can be tricky as it is used by the system as a potential buffer address for conversion from floating point to string.